Redis is an open-source, in-memory data structure store that can be used as a database, cache, and message broker, streaming engine.
Redis stands for Remote Dictionary Server and is fundamentally different from traditional databases. Rather than storing data on disk like PostgreSQL or MongoDB, Redis keeps everything in RAM (memory), making it exceptionally fast for read and write operations.
The Problem Redis Solves
Consider a typical web application flow:
User → Server → Database (query, join tables, compute) → ResponseThe Problem:
- Complex queries requiring multiple table joins which is expensive in terms of time and resources.
- Every page refresh or request repeats the entire process
The Solution: Redis Caching
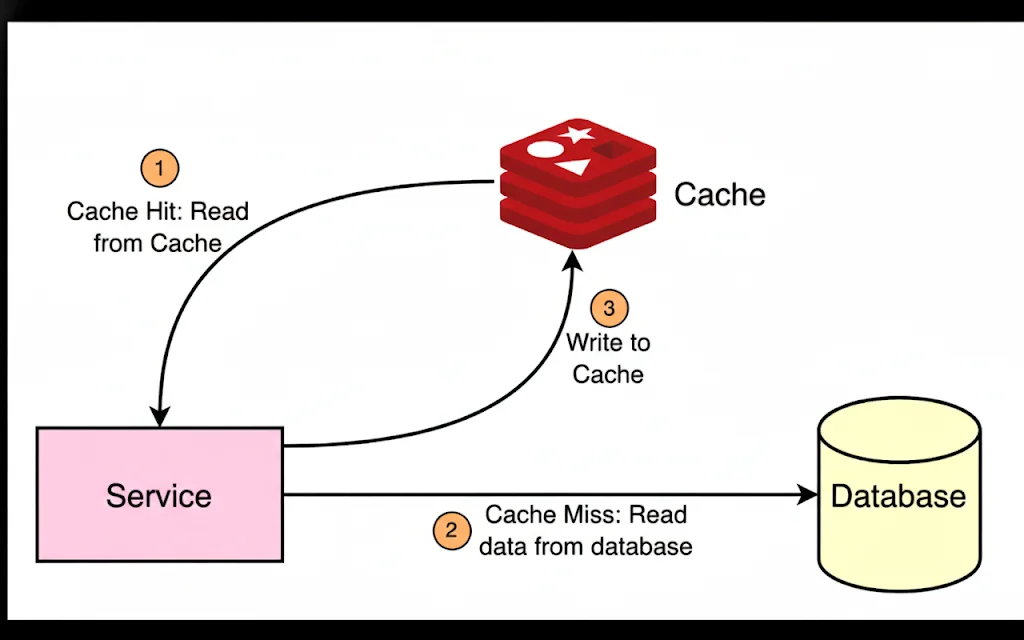
With Redis, frequently accessed data is cached in memory with a time to live(TTL), so subsequent requests get instant responses without hammering the database.
How redis works internally
In-Memory Storage
Traditional databases store data on disk. Reading or writing data on disk requires system calls, filesystem logic, and I/O scheduling, which adds significant overhead and increases latency.
Redis stores all data in RAM, so data access happens directly in memory. Accessing RAM is much faster than accessing disks (HDDs or SSDs) because it avoids disk I/O, context switches, and filesystem overhead. Memory access is also highly predictable, since the CPU can access any memory location in nearly the same amount of time, unlike disk storage where access time varies due to seek time, controller overhead, and queueing.
O(1) Hash Table Lookups
Redis internally uses hash tables (dictionaries) as its core data structure for storing key–value pairs. A hash function maps each key directly to a memory location, enabling constant-time (O(1)) average complexity for read and write operations.
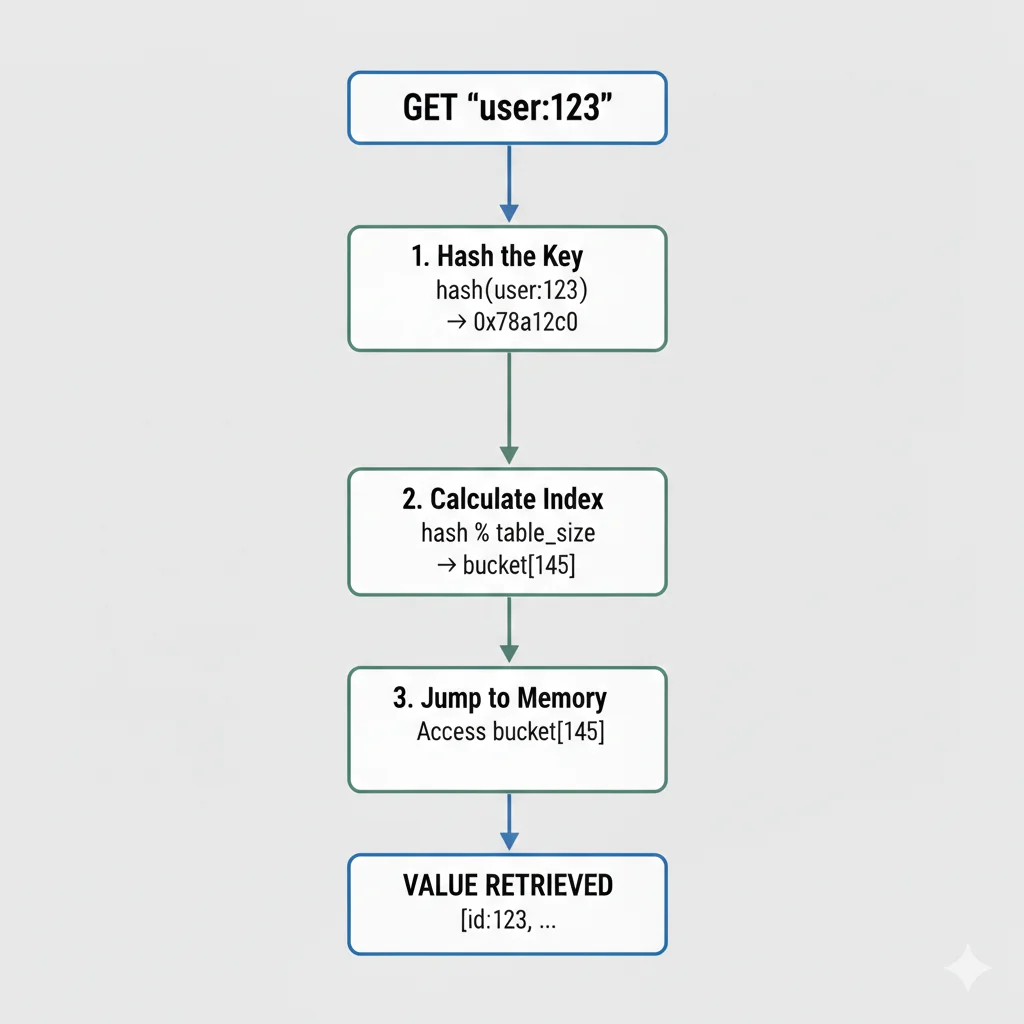
Whether Redis stores 1 key or 100 million keys, the number of operations stays nearly the same because tookup time is independent of dataset size. Which requires not disk I/O, iteration over keys or traversal.
Buckets
Buckets are an array in RAM. Each bucket is a simple pointer (8 bytes on 64-bit systems) that points to a key–value entry:
┌─────────────────────────────────┐
│ Bucket Array (in RAM) │
├─────────────────────────────────┤
│ bucket[0] → NULL │
│ bucket[1] → dictEntry │
│ bucket[2] → NULL │
│ bucket[3] → dictEntry │
│ bucket[4] → dictEntry │
│ ... │
└─────────────────────────────────┘Each dictEntry (the actual key–value pair) contains:
dictEntry {
key_ptr (pointer to the actual key)
value_ptr (pointer to the actual value)
next_ptr (pointer to next entry if collision)
}Hash Table Growth & Resizing
When the bucket array becomes too full, multiple keys may hash to the same bucket, causing collisions and longer chains. This increases lookup time. Redis solves this by allocating a larger array and rehashing keys, reducing collisions and keeping average lookup O(1)
How it works:
-
Initial array is small it normally starts with 4 buckets (32 bytes). Each key added uses one pointer slot.
-
Growth trigger when
load_factor ≥ 1(number of keys ≥ number of buckets). Redis knows the array is at max capacity. -
Create a new array with double the size. Size always stays a power of 2: 4 → 8 → 16 → 32 → 64 → 128 → …
-
For each key in the old array, recalculate its hash and find its new position. Move entries bucket-by-bucket into the new array.
Example:
Old array (4 buckets)
bucket[0] → entry1 (user:1)
bucket[1] → entry2 (user:2)
bucket[2] → NULL
bucket[3] → entry3 (user:3)
New array (8 buckets)
bucket[0] → NULL
bucket[1] → entry2 (user:2) ← rehashed to new position
bucket[2] → entry1 (user:1) ← rehashed to new position
bucket[3] → entry3 (user:3) ← rehashed to new position
bucket[4] → NULL
...Redis doesn’t stop everything to rehash. Instead:
- Create new array (double size)
- Rehash gradually — bucket by bucket during normal operations
- Spread work — each command moves a small portion
- No pauses — clients experience no latency spikes
Client 1: SET key1 value1 ← triggers growth
├─ Create new 8-bucket array
├─ Rehash 1 bucket from old array
✓ Return to client
Client 2: GET key2
├─ Lookup in old/new array
├─ Rehash 1 more bucket
✓ Return to client
Client 3: GET key3
├─ Lookup in old/new array
├─ Rehash 1 more bucket
✓ Return to client
...work spreads over many commands...This keeps Redis responsive even during growth. Clients never experience blocking.
Collision Handling
When different keys hash to the same bucket, Redis uses separate chaining (linked lists):
bucket[10] → entry1 → entry2 → entry3 → NULLSingle-Threaded Event Loop
Redis uses a single-threaded event loop with non-blocking I/O to handle thousands of concurrent clients efficiently. This architecture eliminates:
- Context switching overhead — CPU doesn’t waste cycles switching between threads
- Lock management complexity — no need for synchronization primitives
- Race conditions — sequential execution guarantees atomicity
Why Single-Threaded is Fast
-
The Problem with Multi-threading: Ensuring data correctness (like
count++) requires Pessimistic Locking (mutexes), causing threads to block while waiting for locks. -
IO Multiplexing: Redis uses epoll/kqueue to monitor thousands of TCP connections. The OS notifies Redis only when data is available in the kernel buffer, so it never blocks waiting for network I/O.
-
Network is Slow, Memory is Fast: Network I/O takes milliseconds; RAM operations take nanoseconds. Redis waits for slow network data, then executes the fast memory operation instantly.
The Internal Event Queue
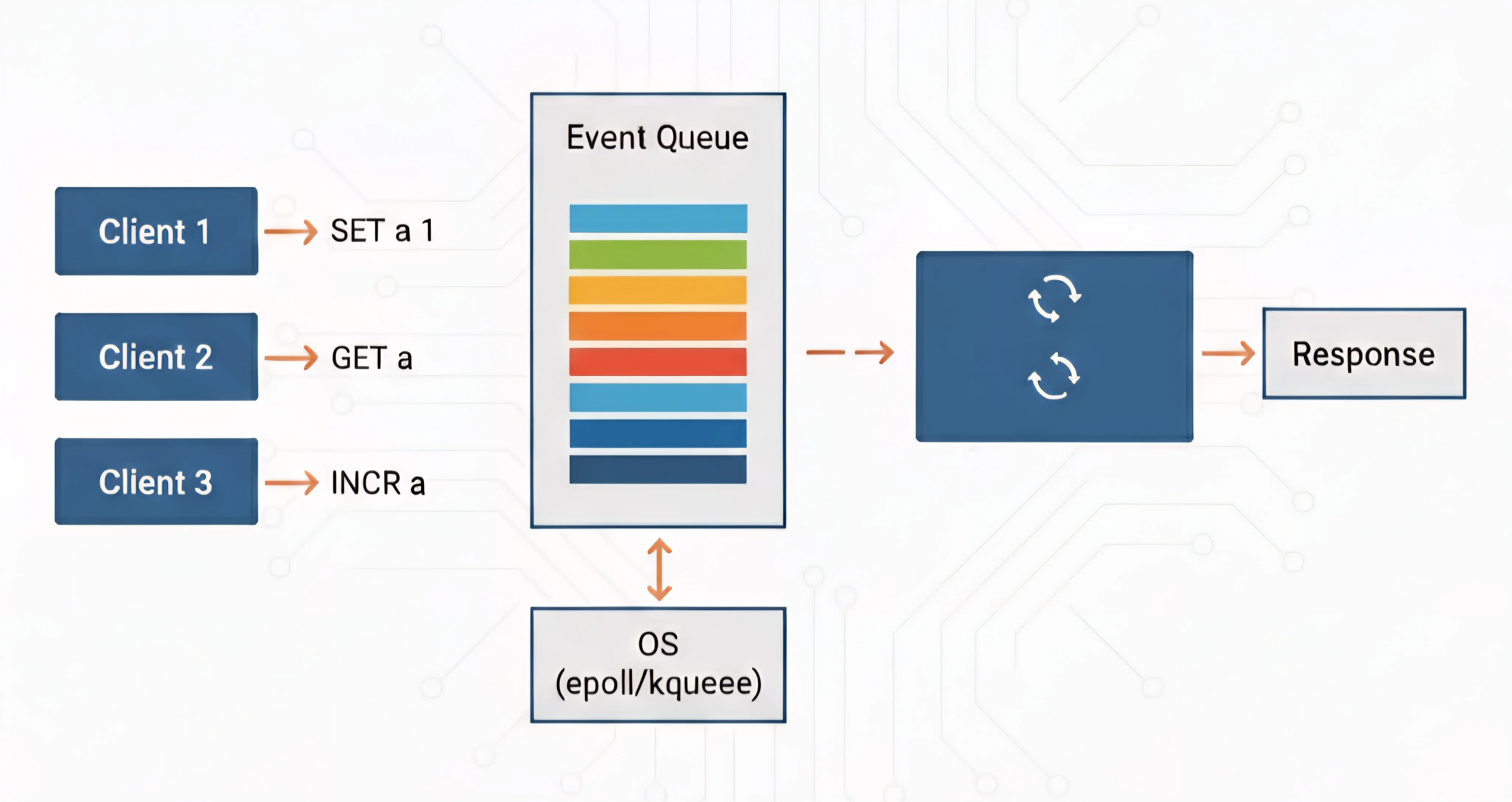
Even though Redis is single-threaded, it uses an internal event queue to handle concurrent clients.
How it works:
- OS notifications — epoll/kqueue notifies Redis when a client connects, sends data, or a socket is ready for writing
- Event queue — Notifications are pushed into Redis’s internal queue (managed by ae.c event library)
- Event loop — Continuously polls the event queue, processes each command atomically, sends the response back to the client, and repeats without blocking.
Optimized Data Structures
Redis achieves high performance through simple, well-optimized in-memory data structures like strings, hashes, and lists. These structures are designed for minimal CPU usage, enabling operations like lookups, inserts, and deletions to execute in constant or near-constant time. Unlike traditional databases that must optimize for disk storage and complex queries, Redis optimizes for speed by keeping data in RAM with efficient structures.
C Implementation
Redis is written in C. So, it has much more control over system resources. It manually manages memory (using malloc and free) and avoids the unpredictable delays caused by garbage collection found in higher-level languages like Java.
Common Use Cases
- Caching Layer: To reduce the load on slow disk-based databases
- Session Storage: Store user sessions and temporary data with automatic expiration (TTL).
- Real-time Analytics: Count page views, track active users, or maintain leaderboards with atomic operations.
- Message Queues: Using its Pub/Sub (Publish/Subscribe) feature for real-time messaging, such as in chat applications.
- Rate Limiting: Implement sliding window counters to throttle API requests.
- Real-time Collaboration: Power live notifications, presence tracking, and collaborative features.